
Designing Resilient API's
Learning how Netflix does it

Friday evening. You just left office and reach home. You order a pizza, tuck in your bed and start Netflix, because it’s finally time to watch that movie.
Sounds good right? But wait, Netflix doesn’t load.

Refresh. Still not working. Refresh. Refresh…..still not working.
Meanwhile, at the Netflix headquarters, David(an intern) is busy wondering as to how the Netflix streaming API’s availability is suddenly going down.
Well David, I think it’s time we all learn about API resiliency and how to create fault tolerant systems at scale.
What is an API - An API is nothing but a way for two applications to interact with each other. Sounds simple, right?
Well there can be multiple reasons for this to break -
Resource starvation
Network failure
System overload(sudden increase in number of requests)
Bad configuration or bad request
How do we then create a system that is fault tolerant and the API’s are as resilient as they can get. Well, let’s learn.
Principles of resiliency -
In case a downstream service(dependent service) call fails, the user experience should not break.
The API should take corrective action and follow another path, if the dependent service fails.
Fault Tolerance is a Requirement, Not a Feature
The Netflix API receives more than 1 billion incoming calls per day which in turn fans out to several billion outgoing calls (averaging a ratio of 1:6) to dozens of underlying subsystems with peaks of over 100k dependency requests per second.
A single service failing can choke an entire API and consume a lot of system resources. For the risk involved, Netflix uses a combination of fault tolerance approaches:
Circuit Breakers
Network Timeouts and Retries
Separate Threads on per-dependency thread pools
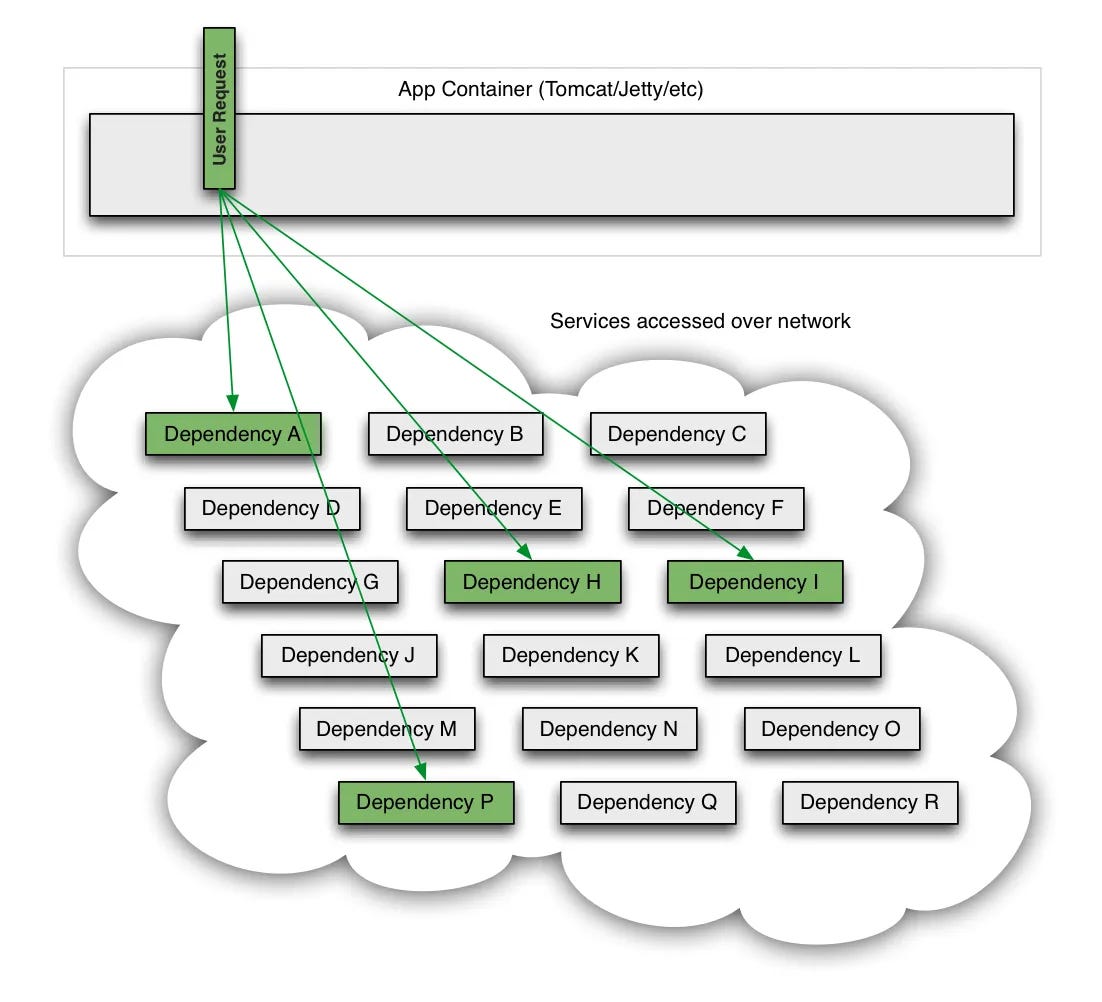
Most dependency calls uses their own separate thread-pool. If a dependency fails, it saturates it’s own thread pool, and all incoming requests would be rejected, rather than consume the entire system resources. Any retries, if configured, use threads from the same pool. Having a thread-pool allows the system to put a upper limit on the number of threads, and hence, prevent over-utilization of resources due to outlier events/services.
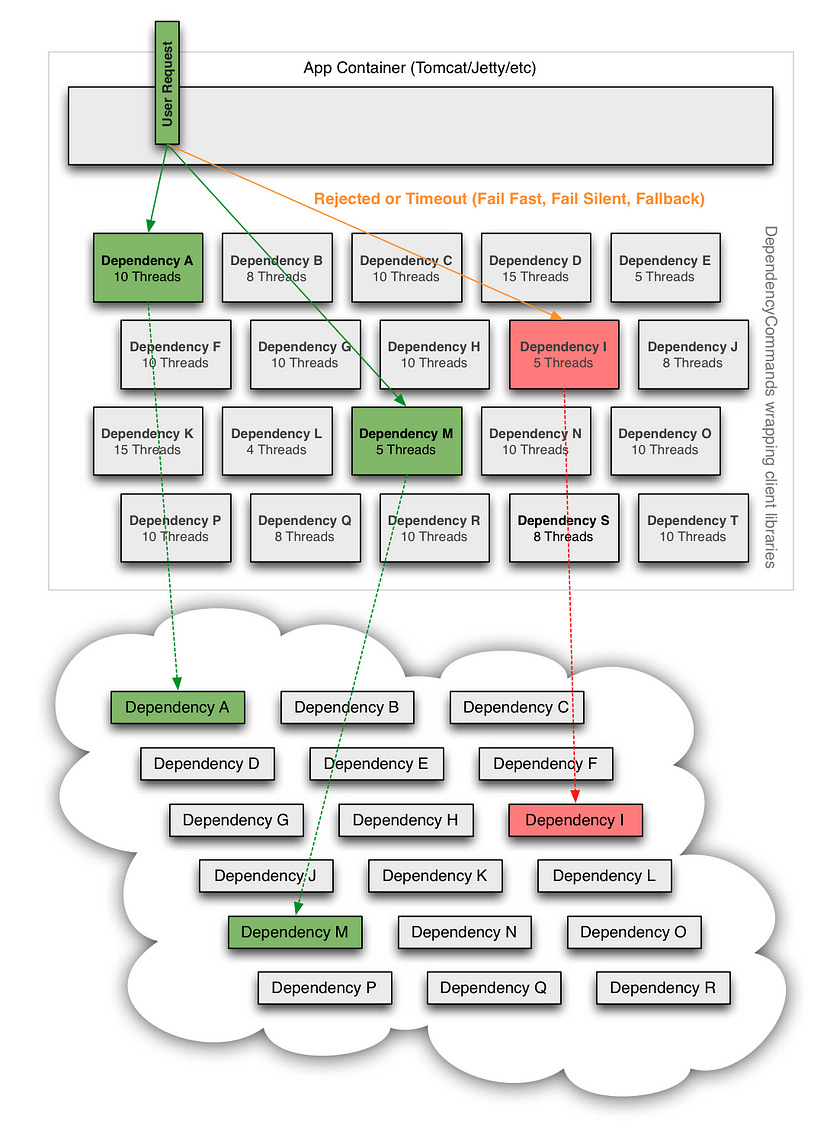
**Above images taken from sources mentioned at the end
Based on the first principal of resiliency, the streaming of movies and shows should continue when API failure happens, even if the experience is slightly degraded and less personalized. Netflix does this through graceful fallback mechanisms. Calls to service dependencies track the result of each call, and in case a service is failing too often, Netflix stops calling them and serve fallback responses. Some calls are then periodically sent to the service to check the status, and if they succeed, the calls are opened for all traffic.
This is precisely the CircuitBreaker pattern. Let’s understand how that works out :
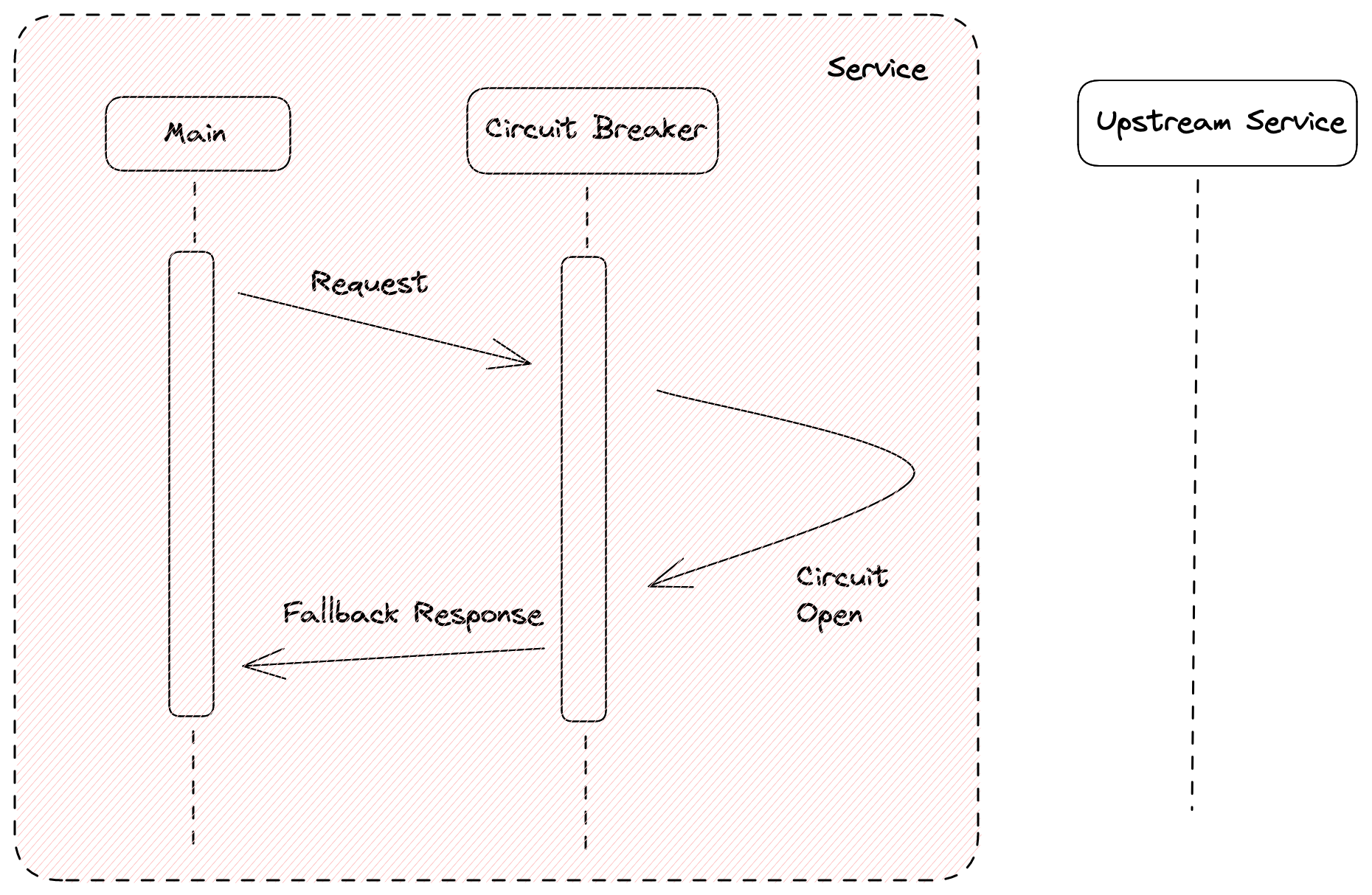
Our “main” method calls the circuit breaker, which in turns calls the upstream service. The upstream service then processes the request and returns the response to the circuit breaker, which in turn returns it to the original caller if there is no error.
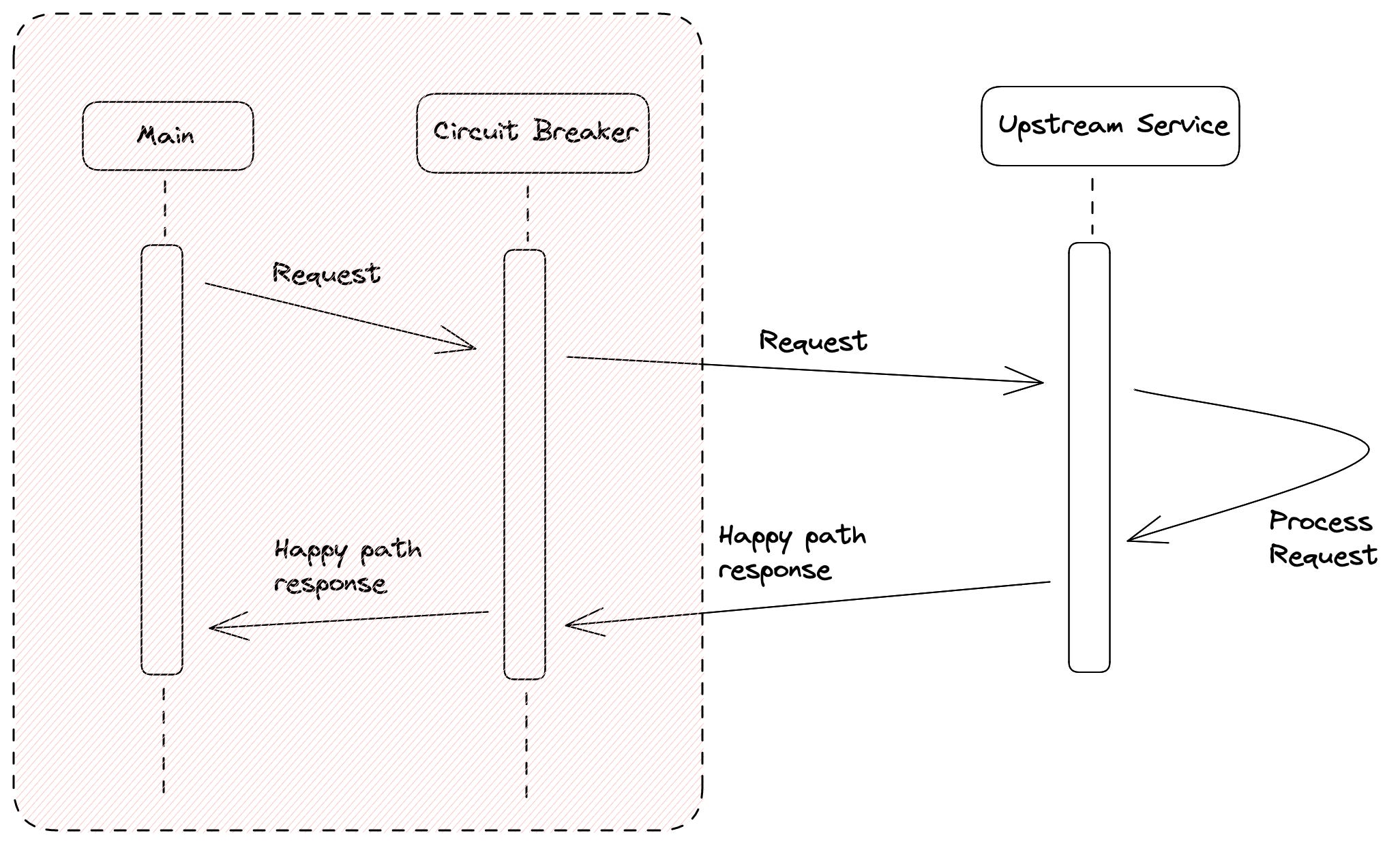
Now, let’s look at what happens when the upstream service fails.
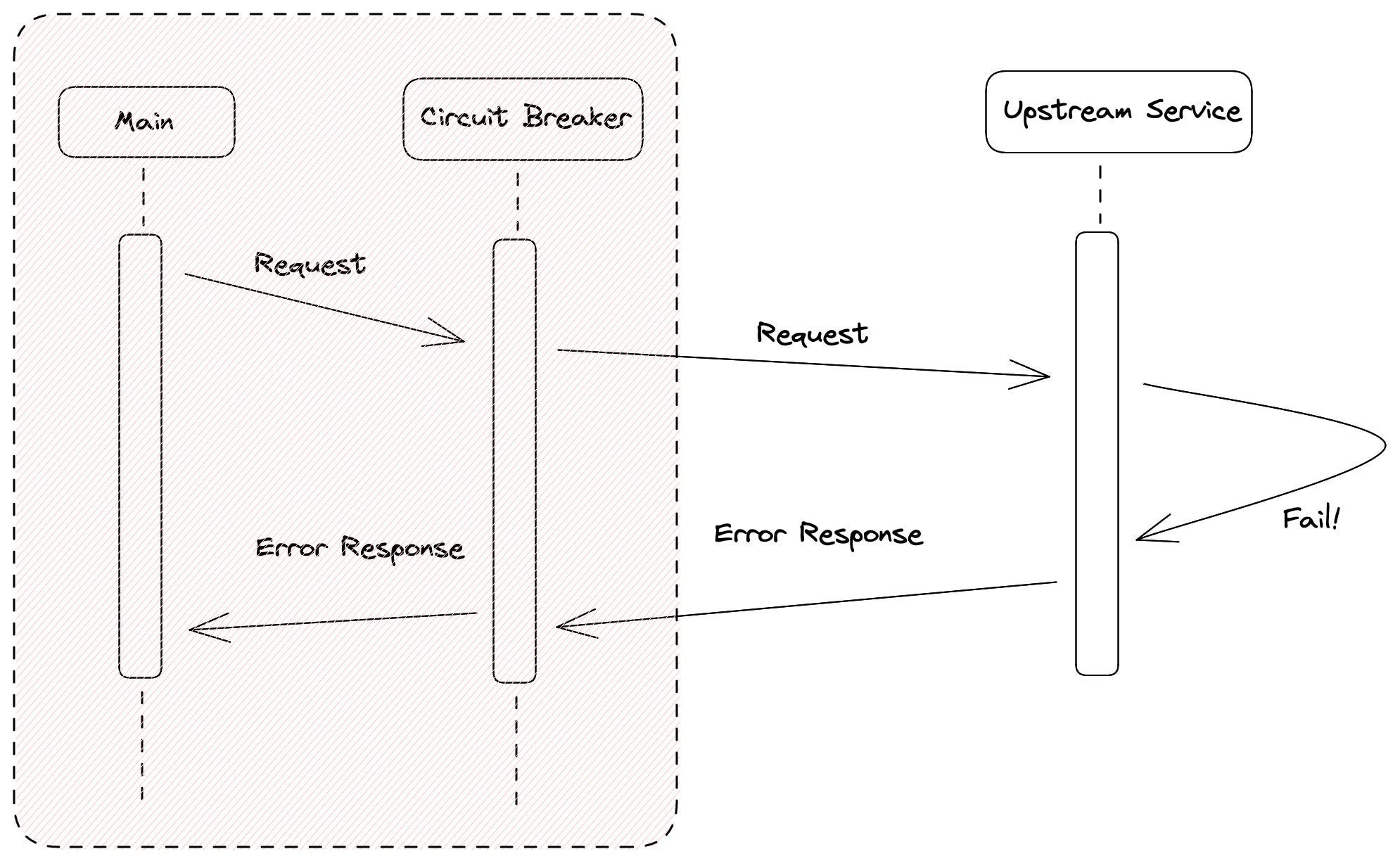
The request path is same. You must be wondering, what have we gained from this. For this specific request, nothing. But let’s assume, all requests for the past 5 seconds have failed. The circuit breaker keeps a count of the number of requests that have failed within a given time-period, and if that number exceeds a threshold, it opens the circuit and prevents all subsequent requests to upstream services. In case of Netflix, instead of returning an error response, a fallback response is sent.
This becomes important for three reasons :
The user is still able to see a fallback response, although slightly degraded and less personalized.
Sending more requests to the upstream service will not help since we will still get an errored response.
Bombarding the upstream service with requests will not allow it to recover and instead, gets overloaded with requests.
Netflix’s CircuitBreaker implementation goes further than this and can be triggered in a few ways:
A request to the remote service times out
The thread pool or task queue is currently are at 100% capacity
The client library used to interact with a service dependency throws an exception
Netflix tracks requests to all service dependencies over a 10 second rolling window and discards request stats older than 10 seconds.
Netflix receives around 20,000 requests per second during peak traffic. For a 10 second duration, that translates to 200,000 requests from clients. Each request calls internal APIs and those 200,000 requests easily translate to 1,000,000+ requests into upstream services. For Netflix, a lot can happen in those 10 seconds.When the circuit breaks, fallback is implemented using one of the following three approaches:
Custom Fallback: Using locally available data on API Server(like cookie or local JVM cache) to generate a fallback response.
Fail Silent: The fallback method in this case returns NULL and is used when the data provided by the service being invoked in optional.
Fail Fast: In case the service being invoked requires data or there’s no good fallback, a 5xx response is sent back. This usually impacts the UX, but also allows the service to recover fast.
Another API design practice is to reduce the response payload is introduction of Partial Response, which help reduce network memory and CPU resources. The Partial Response strategy is like an SQL select statement, where you specify what you need and get only that result back.
Think of a client request to get user from an API.
GET /user/{id}Response:
[
{
"results": [
{
"gender": "male",
"name": {
"title": "mr",
"first": "Abby",
"last": "Tiger"
},
"address": {
"street": "Amsterdam Road",
"city": "New York City",
"state": "New York",
"postcode": 12027,
"coordinates": {
"latitude": "-37.4061",
"longitude": "-95.1859"
}
},
"email": "abby@gmail.com",
"login": {
"uuid": "0aaaa5ec-ab09-4720-b092-81610a218d55",
"username": "orangecat573",
"password": "111111",
"salt": "OUdLDkdm",
"md5": "64b62e0595cff0e112ed8d08364acc55",
"sha1": "84523e164a58b81f379b7cc86330dcaeeeee47cc",
"sha256": "1d5e441f6d2b5cb98c88741efe4993afe48327f18b6097010ca37f8c9eda3088"
},
"language": ["english", "hindi"],
"genre": ["Action","Drama"],
"dob": {
"date": "1950-05-19T13:38:56Z",
"age": 69
},
"phone": "0061-0583330",
"picture": {
"large": "https://randomuser.me/api/portraits/men/11.jpg",
"medium": "https://randomuser.me/api/portraits/med/men/11.jpg",
"thumbnail": "https://randomuser.me/api/portraits/thumb/men/11.jpg"
}
}
]
},
This has a lot of information. But what if our service only needs specific information, like address, languages, genre for a movie recommendation.
The API can then be modified to get the specific fields.
GET /user/{id}?fields=results(address, languages, genre) Response:
[
{
"results": [
{
"address": {
"street": "Amsterdam Road",
"city": "New York City",
"state": "New York",
"postcode": 12027,
"coordinates": {
"latitude": "-37.4061",
"longitude": "-95.1859"
}
},
"email": "abby@gmail.com",
"login": {
"uuid": "0aaaa5ec-ab09-4720-b092-81610a218d55",
"username": "orangecat573",
"password": "111111",
"salt": "OUdLDkdm",
"md5": "64b62e0595cff0e112ed8d08364acc55",
"sha1": "84523e164a58b81f379b7cc86330dcaeeeee47cc",
"sha256": "1d5e441f6d2b5cb98c88741efe4993afe48327f18b6097010ca37f8c9eda3088"
},
"language": ["english", "hindi"],
"genre": ["Action","Drama"]}
]
}
[**The metadata will always be returned.]
The modified response reduces the size of the response received significantly. And for systems like Netflix, which receive billions of requests daily, this saves a lot of memory and CPU.
Sources :