

Principle #1 : Kubernetes APIs are declarative rather than imperative.
We don’t tell the system to start a container on a particular machine or provide exact set of instructions to reach a desired state. We also don’t need to write a monitor system, or tell the system what to do if the system deviates.
You define the desired state, and the system works towards achieving that state.
The following yaml file in Kubernetes will create a deployment - a pod along with two copies of that pod will be created. All we had to do was define what type of system we want, how many copies we want, what container we want to run, on what port should that container run, and Kubernetes will create the rest.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongodb-deployment
labels:
app: mongodb-deployment
spec:
replicas: 2
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb
image: mongo
ports:
- containerPort: 27017
This also helps with Automatic recovery. If a node crashes, Kubernetes will take care of recovering that.
Principle #2 : The Kubernetes control plane is transparent. There are no hidden internal APIs.
Before :
Master : provides exact set of instructions to drive node to desired state.
Node : executes instructions.
Master : monitors nodes, and provides further instructions if state deviates.
After :
Master : defines desired state of node.
Node : works independently to drive itself towards that state.
Think of the Kubernetes API server to be at the center of everything that is happening in a kubernetes cluster. It’s not just the developer, but every other component too interacts with the Kubernetes API server. When a node comes up, it monitors the Kubernetes API server and reports it’s availability and capacity information, such as CPU and memory resources. The API server then updates the nodes information in the cluster’s state information stored in etcd.
The scheduler component in Kubernetes periodically examines the cluster's state and the workloads waiting to be scheduled. It then makes decisions on which nodes to assign each workload to based on factors such as available resources, workload requirements, and any constraints specified in the workload's configuration. The scheduler creates a binding between the selected node and the workload and stores this information in the API server.
The kubelet component on each node watches the API server for changes in the assigned workloads and updates the node's local state accordingly. The kubelet then starts the containers associated with the assigned workload and monitors their health status, reporting back to the API server.
So instead of having a centralized system, where the decision is being sent out, every component is responsible for its own health and for keeping itself running.
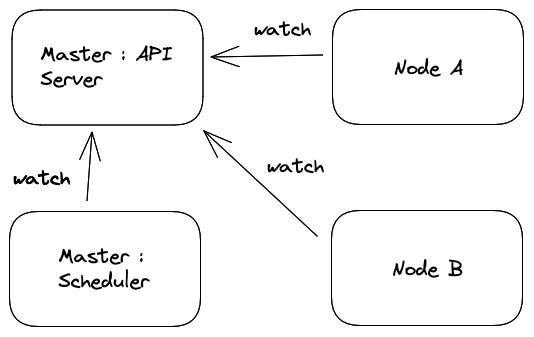
This way, if a node goes down, once it comes back, it can directly reach out to the API Server to figure out what it needs to do.
In a large system with a huge number of components, having a mechanism(this is called level triggered systems) where each component is responsible for it’s existence and reaching out to the API server for its work is more extensible as compared to a system where a particular component is tasked with reaching out to each component to see how they are doing(this is called edge triggered systems). The user can customize things according to requirements.
Principle #3 : Meet the user where they are.
Before : App must be modified to be Kubernetes aware, so that stuff like ConfigMaps and Secrets can be accessed.
After : If app can load config or secret data from file or environment variables it doesn’t need to be modified.
For legacy systems or systems that aren’t using Kubernetes, there should be minimum inertia to help them transition to Kubernetes. One such usecase is Configmaps and Secrets. Ideally, there should be a way to load the configs from a file and environment variables. This is what Kubernetes does. It minimizes hurdles for deploying workloads on Kubernetes and increases adoption.
There is another Kubernetes component that is used stateful applications. Containers are ephermeral, meaning that they can die any time. And with this, they take away any data that they might have. In comes Volumes. Volumes in Kubernetes is essentially a directory or a storage location that is accessible to more than one containers running in a pod. Volumes store and persist data across containers.
Principle #4 : Workload Portability
Kubernetes decouples distributed system application development from cluster implementation and make kubernetes work like a true abstraction layer.
As long as application developers use the Kubernetes API and put it to work, it handles stuff really easily. Kubernetes is cloud and cluster agnostic, so you can basically use cloud platforms like GCP/AWS/Azure and container platforms like Docker, all of them well with Kubernetes.
More Posts in this series :
Waiting for more such articles. Thanks for taking the time to share your knowledge!