

Who To Follow(WTF) Architecture
* Cassovary
The heart of Twitter’s WTF service is the Cassovary in-memory graph processing engine, which assumes that there is sufficient memory to hold the entire graph. The graph is immutable once loaded into memory. Fault tolerance is provided by replication, i.e running multiple instances of Cassovary, each holding a complete copy of the graph in memory. Cassovary provides access to the graph via vertex-based queries such as retrieving the set of outgoing edges for a vertex. These types of queries are sufficient for a wide-range of graph algorithms such as BFS, DFS. Cassovary is multi-threaded, where each query is handled by a separate thread.
How does Cassovary internally works?
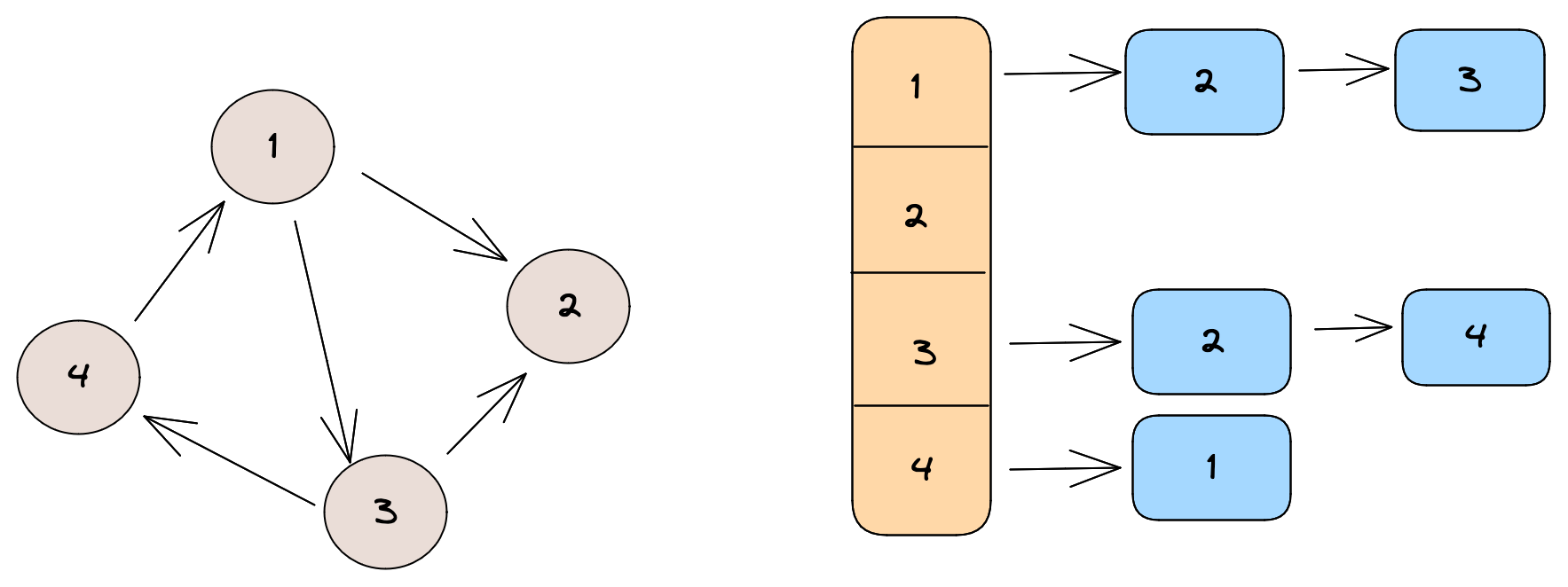
Adjacency list for directed graph
A naive implementation of adjacency list and graph storage would store the adjacency list of each vertex in a separate object, but that leads to additional overhead for JVM (Cassovary is written in Scala), since most of the objects would be small and would require additional overhead in the form of object headers. Since we are storing the entire graph on a single machine, we would want to minimize this wastage of space.
Hence, Cassovary stores the graph as optimized adjacency list. The adjacency list of all vertices is stored in large stored arrays and the vertex object maintains indexes to this list. The vertex data structure holds pointers to the part of the shared array that consists of its adjacency list in the form of a start index and length.
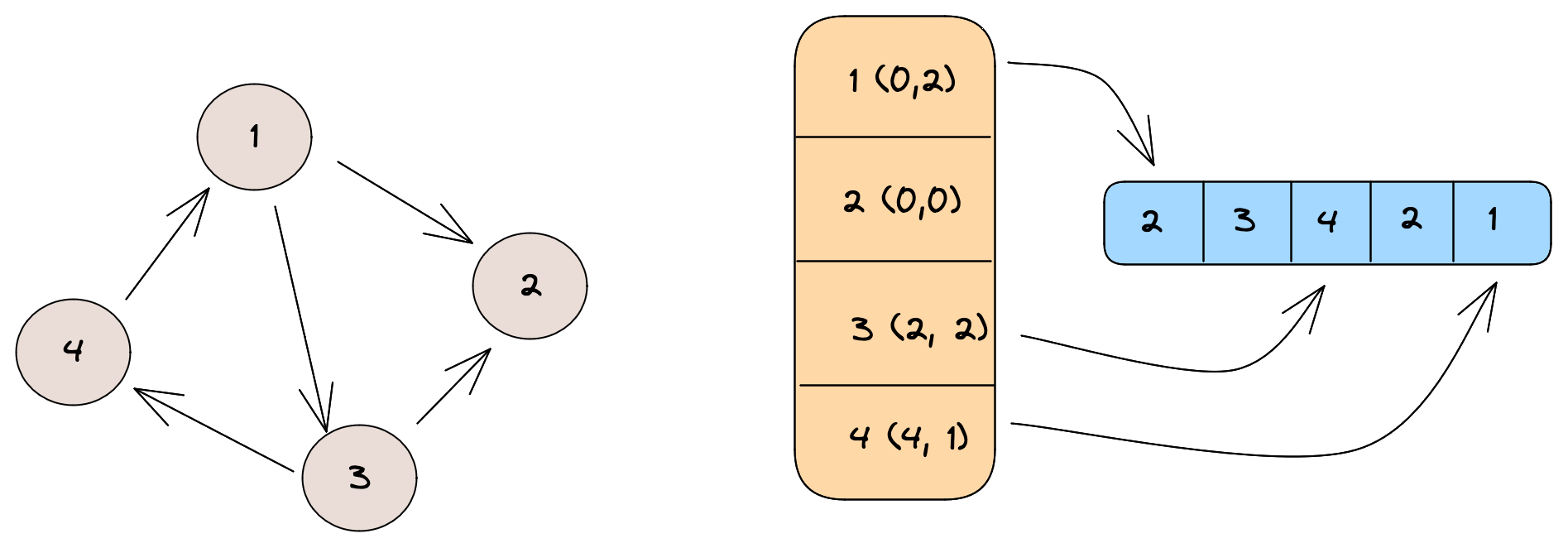
Pictorial representation of how an adjacency list in Cassovary might look like. The first element inside brackets represents the start index and the second element represents the length.
Daily snapshots of the Twitter graph from FlockDB are imported to Hadoop data warehouse and on completion, each graph is loaded into memory on the Cassovary servers.

Active users who consume all their recommendations are requeued with much higher priority, to that they can be shown a newer refreshed recommendation feed. Due to the size of the twitter graph, the Cassovary graphs are updated just once a day. But this is problematic for new users, since recommendations will not be immediately available on joining. Making high-quality recommendations for new users is difficult, because of the lack of information on them. A new user, however, needs a community to engage with, to turn into to an active user. New users are hence given higher priority in the Cassovary queue and are moved to the front of the queue, so that recommendations are provided to them based on whatever information is available from the last snapshot.
Twitter clients(such as iPhone/mobile apps, website) then call Blender, which is the service end-point responsible for fetching recommendations from Fetchers.
Recommendation Algorithms
1. Circle of Trust
A user’s circle of trust(set of other users that this user trusts) is generated by an egocentric random walk. In an egocentric random walk, the agent’s decision making process is not solely based on random choices but also takes into account other factors, like the agent’s personal characteristics, preferences or biases.
Cassovary computes the circle of trust in an online fashion, given a set of parameters. It computes the top k-nodes with highest PPR (Personalized Page Rank) value. PPR is used in user recommendation systems and is similar to PageRank, wherein it generates personalized rankings for other users that reflected the user’s interests. Cassovary dynamically computes a user’s circle of trust by performing the random walk from scratch every time for fresh results. Think of it as calculating the probability of reaching a random-node from a source vertex, based on factors like interests and similarities.

2. SALSA for User Recommendation
Before we talk about SALSA, let’s talk about something called “Hubs” and “Authority”. In the context of google search, envision a webpage as a hub that is connected to numerous other webpages in a specific search. On the other hand, an authoritative webpage can be regarded as one created by someone who has written articles or delivered talks on a particular topic.
Essentially, an authority is a web page that is linked to many other webpages. They are considered important because they are seen as reliable sources of information on a particular topic, and are more likely to contain high quality content. While a hub is a page that contains links to a lot of useful authority pages. A page with a high hub score is likely to link to many pages with high authority scores, and vice-versa.
Pages with high hub scores are considered important for browsing the web, while pages with high authority scores are considered important sources of information. Pages with both high hub and authority scores are considered to be the most important and ranked the highest.
SALSA (Stochastic Approach for Link-Structure Analysis) is an algorithm originally developed for web search, but has been modified by Twitter for user recommendation purposes.
How does the algorithm work ?
The “hubs” left side is populated with the user’s circle of trust (discussed above). Twitter uses approximately 500 nodes(k=500) from user’s circle of trust. The “authorities” (right) side is populated with users that the “hubs” follow. Once this bipartite graph is created, multiple iterations of the SALSA algorithm are run, which assigns scores to both sides. The vertices on the right hand size are then ranked by score and treated as standard(interested in) user recommendations. The vertices on the left-hand side are also ranked, and this ranking is used as user similarity metric. This solves both problems, finding user recommendations that fulfill the “interested in” and “similar to” criteria. Pages like @espn can serve as authorities (interested in), while users similar to user u can be treated as hubs (similar to).
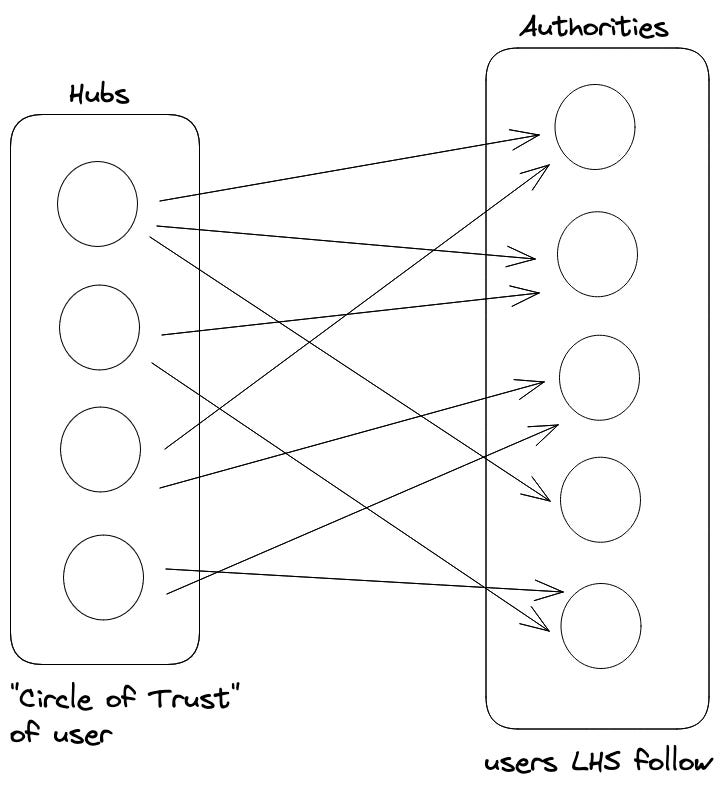
A user u is likely to follow those who are followed by users that are similar to u. These users are in turn similar to u if they follow the same.
Evaluation
Any recommendation system needs to have a framework for continuous evaluation for its success. Twitter broadly uses two types of evaluations -
Offline Experiments on retrospective data - The new algorithm is run on a graph snapshot from say, a month ago. The result obtained would then be compared with the edges that have been added since the time the snapshot was taken, and relevant metrics like precision (True positives/ (True positives + False positives) ) and recall ((True positives/ (True positives + False negatives) )) would be calculated.
Online A/B testing on live traffic - A gold standard for testing web-based products, where a small fraction of the live traffic is subjected to alternative treatment (like a new algorithm).
This however is time-consuming, since we must wait for sufficient traffic to accumulate in order to draw reliable conclusions, which limits the speed at which new features can be rolled out.
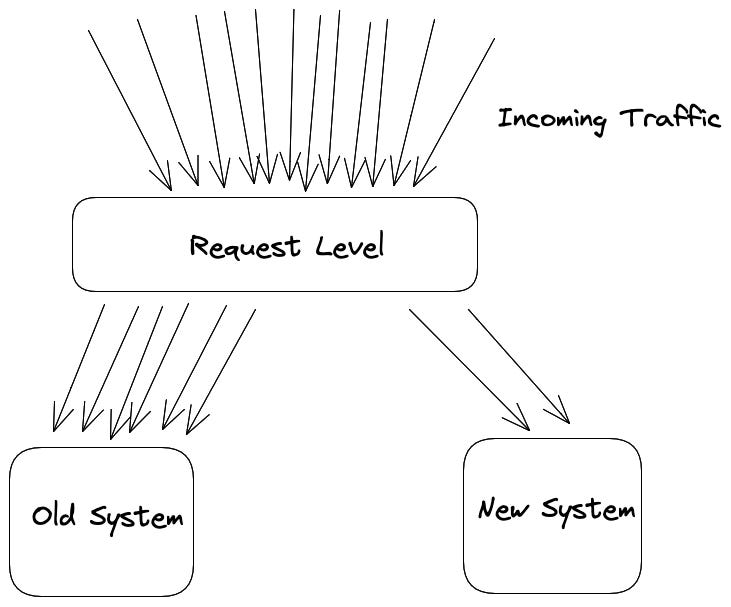
A/B Testing
To capture the impact of a recommendation algorithm, Twitter uses a metric called engagement per impression (EPI), which basically measures the user’s engagement with a recommendation during a given time period, after the user has accepted that recommendation.
Limitations
The WTF architecture built around the graph-on-a-single-server assumption was never meant to be a long term solution, but was designed to provide a high-quality solution that could be developed rapidly and deployed to production. The architecture present significant problems, such as :
Scalability Bottleneck : As the graph grows with more users coming in, the servers would get exhausted.
Limitation on use of metadata : The variety of features that can be exploited by graph algorithms was constrained due to lack of information stored in the graph because of memory limitations. For eg: attaching additional information like bios, hobbies of the vertex(user), edge weights etc would have provided more value to the recommendation algorithm, but was very difficult to accomplish given the memory constraints.
Conclusions :
Given that the product was launched within a span of months by a team of 3 engineers at Twitter and was able to handle the scale of Twitter is impressive.
The paper shows the eventual limitations associated with a single memory architecture.
Random-walk graph algorithms were used to handle user recommendations at a time when machine learning was still not mainstream.